
A couple of weeks ago Dan, Teller’s CTO, asked me if I knew of any open-source and reasonably small language models that could be used for automating some support tasks that pop up within the company from time to time. The initial idea was simple: create a chat-bot like interface for answering support questions about Teller. This is the story of Heath (named in honor of Heath Ledger, who played the greatest supporting role of all time as the Joker in The Dark Knight), the Teller support bot.
A Simple Zero-Shot Approach
A simple approach to this problem is to make use of a zero-shot model which has access to a pre-determined list of questions and answers. If you have a fixed number of questions customers often ask, that don’t require any additional context to answer, this approach can work relatively well. The idea is simple:
- Enumerate common questions into a set of question and answer pairs
- Pass customer queries through a zero-shot classification model to classify the question being asked
- Lookup the answer to the classified question and return it to the customer
There are obvious benefits to this approach. It’s quick and easy, and you don’t have to worry about the support bot going off script. There are also drawbacks. The zero-shot model requires a certain amount of structure to the input. You won’t be able to answer lists of queries or queries that require additional context. This approach also requires that you maintain an ever-growing list of FAQs. You also lose out on the possibility for interaction with a customer.
While a well-executed open-ended generation model would be a more flexible approach, we just wanted to get Heath crawling before we tried to run. The first iteration of Heath made use of a the bart-large-mnli zero-shot classification model from Facebook. Zero-shot classifications models often frame zero-shot classification as a natural language inference problem. Given a sentence and labels, we create a batch of premise-hypothesis pairs. For each pair, we predict the probability that the hypothesis is true or false. For example, given the sentence: “I want to go to France” and the labels “cooking”, “dancing”, and “traveling”, we create the following premise-hypothesis pairs:
{"I want to go to France", "This example is about cooking."}
{"I want to go to France", "This example is about dancing."}
{"I want to go to France", "This example is about traveling."}For each premise-hypothesis pair, we predict the probability that the hypothesis is true, and then normalize the probabilities across all labels to determine the most likely label.
Using Elixir’s Bumblebee library, we can implement a simple zero-shot FAQ model:
defmodule Heath.Models.FAQ do
def ask(input) do
%{predictions: preds} = Nx.Serving.batched_run(
Heath.FAQ,
input
)
%{label: question} = Enum.max_by(preds, fn
%{score: score} -> score
end)
answer(question)
end
def serving() do
{:ok, model} = Bumblebee.load_model({:hf, "facebook/bart-large-mnli"})
{:ok, tokenizer} = Bumblebee.load_tokenizer({:hf, "facebook/bart-large-mnli"})
Bumblebee.Text.zero_shot_classification(
model,
tokenizer,
labels(),
defn_options: [compiler: EXLA]
)
end
defp labels() do
["What is Teller?", "Unrelated"]
end
defp answer(question) do
answers = %{
"What is Teller?" =>
"Teller is the best way users connect their bank accounts to your app.",
"Unrelated" =>
"I'm sorry, but I can't answer that."
}
Map.fetch!(answers, question)
end
endNotice we have to include a “refusal” class to make sure Heath doesn’t answer questions that aren’t about Teller. This approach isn’t perfect, but if you fire up an IEx session you’ll notice it’s not half bad.
And Heath is off the ground!
A Naive Attempt at Open-Ended Generation
While the FAQ model can work well, our end goal for Heath is something a bit more powerful. We want Heath to be able to respond to any question using his knowledge about Teller. A natural solution to this problem is to use a text generation model. I had recently read about Google’s Flan-T5 models and how they proved to be both reasonably sized and competitive with GPT-3. Also, the Flan collection is open-source.
Flan-T5 is a text-to-text generation model designed to follow instructions. We can frame the support task as prompting a pre-trained Flan model with something like:
You are Heath, the Teller support bot. Answer the following support question about Teller. If you don't know the answer, just say you don't know, don't try to make one up.
Question: #{question}
Answer:Of course, it’s unlikely that the pre-trained Flan-T5 models know anything about the common support questions at Teller. To get around this, our initial idea was to just fine-tune Heath on support discussions from the Teller slack. Given a dump of Slack data, we naively generated instruction-response pairs with a heuristic that looked something like this:
- Group adjacent messages by the same user into a single message
- Treat adjacent messages by different users as instruction-response pairs
To pair this data down even further, we can filter instructions only for those that contain a question, e.g. those with a “?” in the string.
This heuristic is incredibly noisy. Support conversations obviously do not follow this simple structure; however, as a means of quickly generating training data to validate this approach, it worked well. With a dataset generated, we fine-tuned the google/flan-t5-large for a few epochs to see what kind of responses we could get from Heath. Surprisingly, Heath did pretty well, but seemed to be easily fooled and would often pull answers out of thin air. The flan-t5-large model also struggled to generate coherent text from time to time.
Giving Heath Some Context
Rather than rely on fine-tuning alone (or even at all), we can give Heath access to information about Teller at inference-time. Most question-answering tasks rely on access to both a question and context in order to generate an answer. By not giving Heath access to sufficient context, we were unfairly asking him to drive blind.
We can give Heath access to information by augmenting his output with retrieved context. In order to give Heath sufficient context, we pulled information from the Teller documentation and blog and embedded them using the sentence-transformers/all-MiniLM-L6-v2 sentence similarity model. We stored all of these embeddings in a FAISS index using ExFaiss.
One challenge during the embedding process is determining the size of context you want to provide to the generation model. Large language models are easily distracted, so you want to ensure the retrieved context precisely answers the question being asked. If you have time to go through your documentation and precisely partition it into information dense chunks, that’s ideal. Our quick solution to this problem was to chunk documents into 256 tokens each. With this approach, you risk cutting sentences in half; however, we we’re just trying to validate an approach before trying to perfect the process.
Once we had created a sufficient index for Heath to access at inference-time, we moved on to implementing our retrieval and generation servings. Once again, we used Elixir, Nx, and the Bumblebee library. The implementation is relatively simple:
- Embed queries using the smaller sentence similarity model
- Search the existing ExFaiss index for the document label most similar to the embedded query
- Retrieve the top-label and add it to the query as context
- Generate an answer for a prompt constructed with the question and context
You can view the full implementation here. You’ll notice it’s only around 100LOC for this entire process.
For this iteration of Heath we used the larger google/flan-t5-xl flan variant with no fine-tuning. The XL model proved to generate more coherent outputs, and was still able to run in a reasonably amount of time on a CPU.
Giving Heath access to context resulted in a big boost in performance. While he would still make up answers from time-to-time, he did significantly better at answering a wide-array of questions about Teller. With what ended up being a few hours of work, we had a decent solution. But, we can do even better still.
Labeling Data With Liveview
With the idea of Heath validated, it was time to do things properly. We needed to label data. We created a simple LiveView application for labeling instruction-response pairs from Slack data:
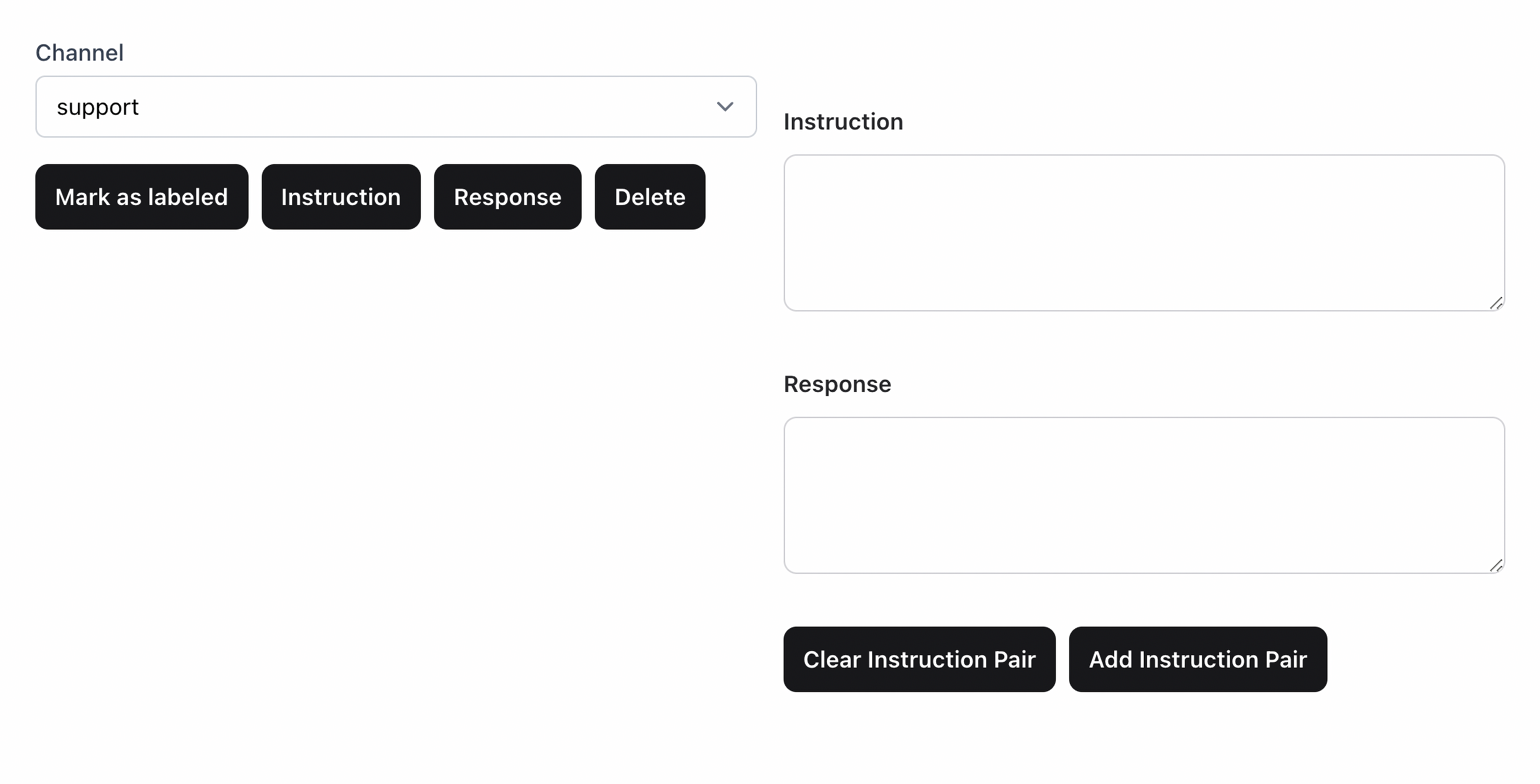
The idea is that we could pour through information available in Slack to generate a proper dataset for fine-tuning Heath, as well as give him access to more information in his index. The labeling process is tedious and boring, but access to quality data is key to success.
Augmenting Heath’s Training Data
A couple of days after starting the labeling process, we had an idea to artificially increase the size of the dataset we currently had.
A recent trend when working with text is to use large language models like GPT-3 to generate training data. Coming up with support questions and answer pairs from Slack data is relatively easy, but it’s kind of tedious. The first quick augmentation strategy we used was to use the documentation to generate question and answer pairs directly. This strategy is simple: we break the documentation up into small chunks, and then prompt GPT-3 to generate 5 question-answer pairs about the paragraph presented. This results in a quick boost in the amount of available training data. The more documentation you have, the more question-answer pairs you can generate.
For support conversations, another simple augmentation strategy is to use GPT-3 to rephrase support questions. The goal of rephrasal is to generate new copies of the same question without changing the original meaning of the question. In our case, we also asked GPT-3 to rephrase the answer according to the question rephrasal. This was done to stop Heath from learning to be repetitive in his answers.
The final, even simpler augmentation strategy we used is to generate question lists from existing labeled data. One thing we noticed is that in practice a lot of customers come with multiple queries at once, listing out questions like:
- What is Teller?
- How do I use Teller?
We can generate a fixed number of new instruction-response pairs by randomly selecting multiple existing pairs (say 2-4) and creating a single instruction-response pair comprised of the list of instructions and responses. This strategy actually proved to work pretty well, in practice Heath does a good job of working with question lists.
With these augmentation strategies, we were able to increase the size of our oiginal dataset of about 200 labeled instruction-response pairs to 2000. In practice, you typically don’t want to rely so heavily on augmented data; however, our observations from fine-tuning Heath on the augmented dataset are that he does better than when trained on just our small set of original labels. Our plan is to go back through the augmented set and remove any erroneous entries, and iteratively improve the quality of Heath’s training set.
Bringing Heath to Life
With a validated approach and a trained model, it was time to bring Heath to life. We created a simple slack application which listens for mentions of Heath and replies to the query in a thread:
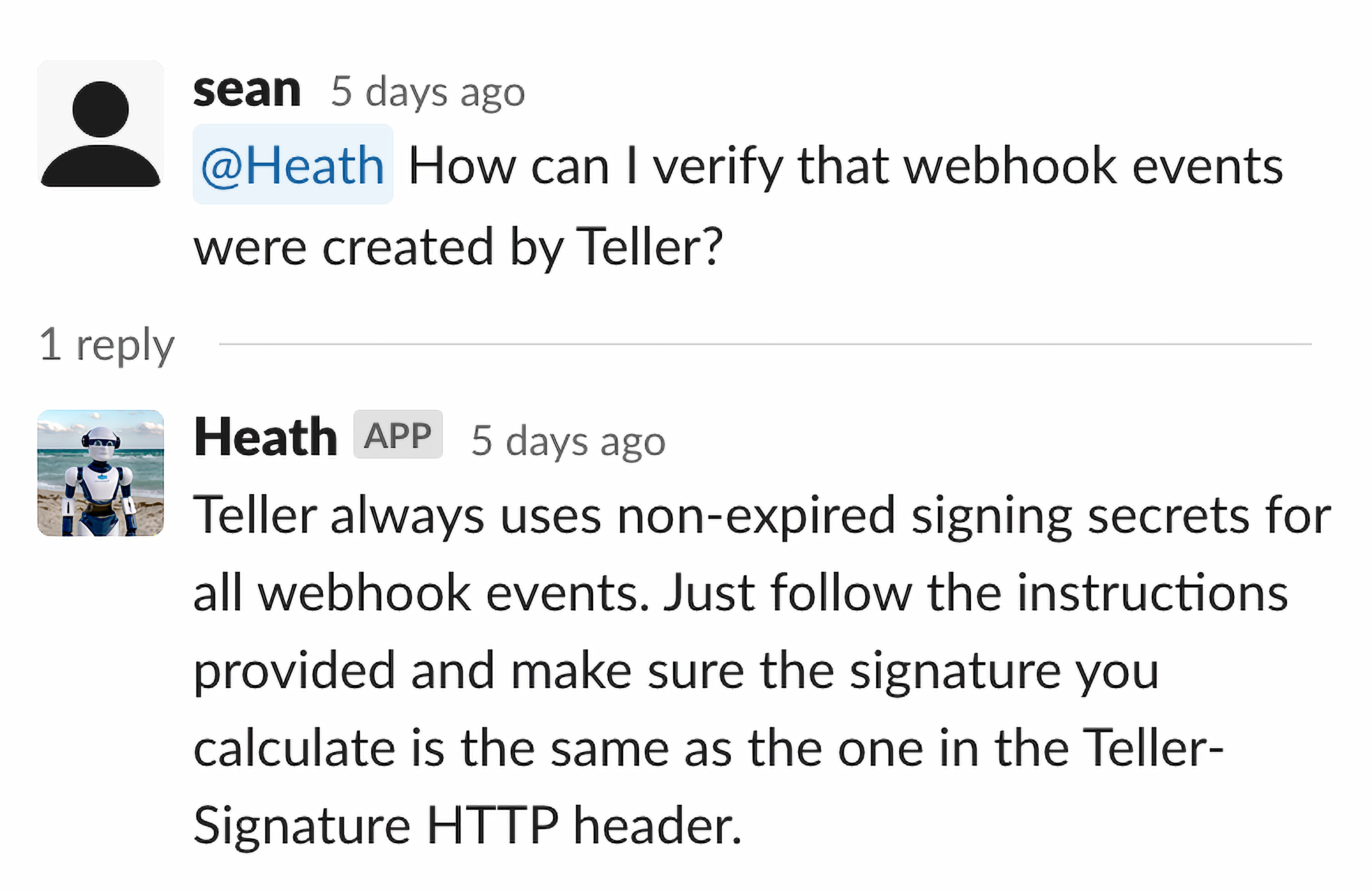
An important part of this process is to collect feedback early and often. We also implemented a simple way to give Heath feedback directly from Slack by issuing corrections:
Right now Heath is in training. In the future, we plan to grow Heath and teach him to use tools, maintain conversations, and more.
We’ve also open-sourced all of the non-Teller specific bits of Heath. This includes Elixir mix tasks for generating datasets from Slack, performing data augmentation, the labeling LiveView, and the actual Phoenix app Heath uses to communicate with Slack. You can find the repository here.