Zelle is the largest peer-to-peer payments network in the United States by any metric you care to slice it by. More than 120 million people are enrolled and more than $600 billion dollars cross its rails annually. In other words, 50% of the adults in the United States are Zelle users. Despite this runaway success you won’t have seen any fintech startups on there; the door has not been opened to them. Given how incredibly relevant Zelle is, the continued inability of fintechs to access it presents a major stumbling block for any new depository-account-with-debit-card type products entering the market.
Today we are excited to announce Bridge, our new product for bringing Zelle to neobanks and other types of non-bank fintech companies that issue their own debit cards and have been historically excluded from Zelle.
Despite not being a direct member of Zelle, with Bridge you can now enroll your users using the debit card PANs you’ve issued them. When a user sends money, their card is debited, and any incoming funds are immediately pushed to their card. In effect the debit card serves as both the entry and exit points to the Zelle network.
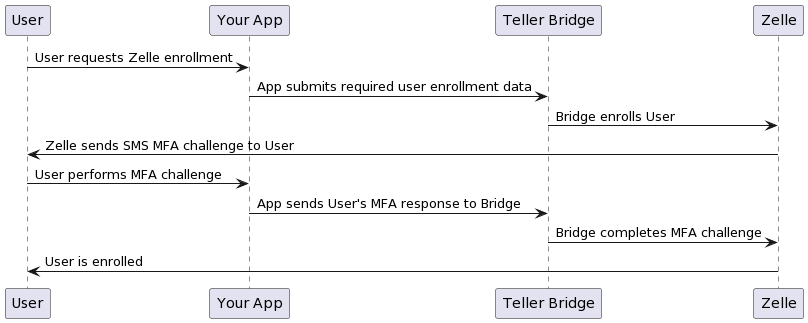
When the user requests to enroll, your app submits the required information to Bridge, which includes the telephone number or email the user wishes to register with Zelle and their card information that you as the issuer already possess. Bridge then submits all of this to Zelle, and after a simple SMS MFA challenge the user is enrolled and ready to send and receive payments.
Enrolling your users on Zelle
Once enrolled your app can send payments and create payment requests on behalf of the user, allowing you to build a fully native Zelle experience in your app as if you were a first-class participant of the Zelle scheme.
All product and company names are trademarks™ or registered trademarks® of their respective holders. Their usage does not imply any affiliation with or endorsement by their holders.
Have you ever wanted to try Teller, but never gotten around to it because of your application code being tightly coupled to Plaid’s API and data schema? Allow me to introduce you to Sidecar.
Sidecar is a zero-code solution for painlessly migrating from Plaid to Teller. It enables you to use Plaid for existing linked Plaid items while enrolling new accounts using Teller, all without any changes required to your application code.
How does it work?
Sidecar is an application provided as a Docker image for you to deploy and run alongside your main application in your own infrastructure. You configure Sidecar with your Teller certificate and then update your application’s Plaid configuration to point towards your Sidecar instance instead of Plaid’s API host.
Integrating Teller is now a simple config change.
Now your application will proxy Plaid API requests via Sidecar, which intelligently routes API calls based on whether the API request is made using a Teller or Plaid access token. When a Plaid token is detected Sidecar transparently proxies the API request to Plaid as usual. However, when a Teller token is used Sidecar translates and reroutes the call to Teller’s API and then translates the API response into the Plaid schema your application is expecting.
With our application configuration updated to use Sidecar let’s take a look at how the application now works.
Plaid's example code configured to use Teller using Sidecar.
With Sidecar eliminating the engineering switching cost and more than 5,000 financial institutions being supported there has never been a better time to take a look at Teller.
Sidecar is provided free of charge to those with legacy applications wanting to use Teller. Contact sales today.
All product and company names are trademarks™ or registered trademarks® of their respective holders. Their usage does not imply any affiliation with or endorsement by their holders.
When it comes to connecting to user financial accounts, it seems like there are no easy choices: you can either partner with a company offering tremendous breadth of integrations that are not particularly reliable, or you can choose a partner with rock-solid, high-quality integrations but more limited in terms of the number banks supported (that would be us 👋).
Today, we are pleased to announce that you no longer have to choose between quality and quantity.
Now you can just have both.
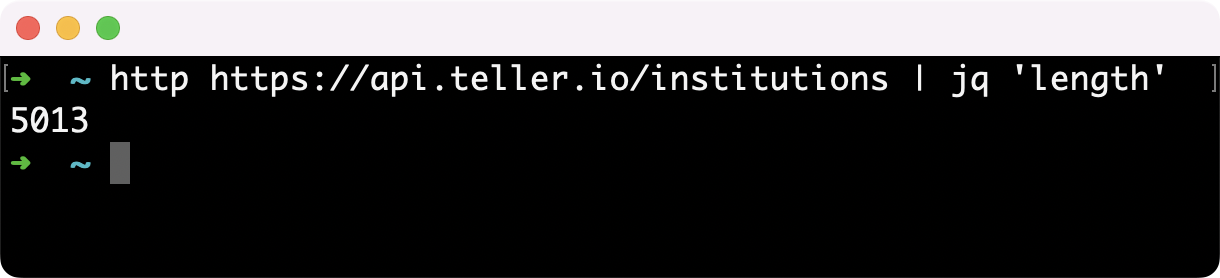
Teller now supports connecting to users’ accounts at more than 5,000 US financial institutions instantly and seamlessly, without compromising on the high quality and reliability that Teller has become renowned for.
By the time you read this it's likely we support even more FI's. Get an up-to-date number from our API.
The Teller engineering and operations teams have been hard at work optimizing and streamlining our workflows to support additional financial institutions. Their dedication is paying off: with 99% of the supported institutions having been added this year, and an incredible 85% of them within the last month!
We won’t stop here. There are around 4,000 banks and 4,000 credit unions in the United States, and we will continue to add more financial institutions with the same velocity and intensity until we achieve 100% coverage. Until that day comes, we are also pleased to announce that we now support same-day microdeposit verification for accounts at institutions we don’t yet instantly connect to.
A couple of weeks ago Dan, Teller’s CTO, asked me if I knew of any open-source and reasonably small language models that could be used for automating some support tasks that pop up within the company from time to time. The initial idea was simple: create a chat-bot like interface for answering support questions about Teller. This is the story of Heath (named in honor of Heath Ledger, who played the greatest supporting role of all time as the Joker in The Dark Knight), the Teller support bot.
A Simple Zero-Shot Approach
A simple approach to this problem is to make use of a zero-shot model which has access to a pre-determined list of questions and answers. If you have a fixed number of questions customers often ask, that don’t require any additional context to answer, this approach can work relatively well. The idea is simple:
Enumerate common questions into a set of question and answer pairs
Pass customer queries through a zero-shot classification model to classify the question being asked
Lookup the answer to the classified question and return it to the customer
There are obvious benefits to this approach. It’s quick and easy, and you don’t have to worry about the support bot going off script. There are also drawbacks. The zero-shot model requires a certain amount of structure to the input. You won’t be able to answer lists of queries or queries that require additional context. This approach also requires that you maintain an ever-growing list of FAQs. You also lose out on the possibility for interaction with a customer.
While a well-executed open-ended generation model would be a more flexible approach, we just wanted to get Heath crawling before we tried to run. The first iteration of Heath made use of a the bart-large-mnli zero-shot classification model from Facebook. Zero-shot classifications models often frame zero-shot classification as a natural language inference problem. Given a sentence and labels, we create a batch of premise-hypothesis pairs. For each pair, we predict the probability that the hypothesis is true or false. For example, given the sentence: “I want to go to France” and the labels “cooking”, “dancing”, and “traveling”, we create the following premise-hypothesis pairs:
{"I want to go to France", "This example is about cooking."}
{"I want to go to France", "This example is about dancing."}
{"I want to go to France", "This example is about traveling."}
For each premise-hypothesis pair, we predict the probability that the hypothesis is true, and then normalize the probabilities across all labels to determine the most likely label.
Using Elixir’s Bumblebee library, we can implement a simple zero-shot FAQ model:
defmoduleHeath.Models.FAQdodefask(input)do%{predictions:preds}=Nx.Serving.batched_run(Heath.FAQ,input)%{label:question}=Enum.max_by(preds,fn%{score:score}->scoreend)answer(question)enddefserving()do{:ok,model}=Bumblebee.load_model({:hf,"facebook/bart-large-mnli"}){:ok,tokenizer}=Bumblebee.load_tokenizer({:hf,"facebook/bart-large-mnli"})Bumblebee.Text.zero_shot_classification(model,tokenizer,labels(),defn_options:[compiler:EXLA])enddefplabels()do["What is Teller?","Unrelated"]enddefpanswer(question)doanswers=%{"What is Teller?"=>"Teller is the best way users connect their bank accounts to your app.","Unrelated"=>"I'm sorry, but I can't answer that."}Map.fetch!(answers,question)endend
Notice we have to include a “refusal” class to make sure Heath doesn’t answer questions that aren’t about Teller. This approach isn’t perfect, but if you fire up an IEx session you’ll notice it’s not half bad.
And Heath is off the ground!
A Naive Attempt at Open-Ended Generation
While the FAQ model can work well, our end goal for Heath is something a bit more powerful. We want Heath to be able to respond to any question using his knowledge about Teller. A natural solution to this problem is to use a text generation model. I had recently read about Google’s Flan-T5 models and how they proved to be both reasonably sized and competitive with GPT-3. Also, the Flan collection is open-source.
Flan-T5 is a text-to-text generation model designed to follow instructions. We can frame the support task as prompting a pre-trained Flan model with something like:
You are Heath, the Teller support bot. Answer the following support question about Teller. If you don't know the answer, just say you don't know, don't try to make one up.
Question: #{question}
Answer:
Of course, it’s unlikely that the pre-trained Flan-T5 models know anything about the common support questions at Teller. To get around this, our initial idea was to just fine-tune Heath on support discussions from the Teller slack. Given a dump of Slack data, we naively generated instruction-response pairs with a heuristic that looked something like this:
Group adjacent messages by the same user into a single message
Treat adjacent messages by different users as instruction-response pairs
To pair this data down even further, we can filter instructions only for those that contain a question, e.g. those with a “?” in the string.
This heuristic is incredibly noisy. Support conversations obviously do not follow this simple structure; however, as a means of quickly generating training data to validate this approach, it worked well. With a dataset generated, we fine-tuned the google/flan-t5-large for a few epochs to see what kind of responses we could get from Heath. Surprisingly, Heath did pretty well, but seemed to be easily fooled and would often pull answers out of thin air. The flan-t5-large model also struggled to generate coherent text from time to time.
Giving Heath Some Context
Rather than rely on fine-tuning alone (or even at all), we can give Heath access to information about Teller at inference-time. Most question-answering tasks rely on access to both a question and context in order to generate an answer. By not giving Heath access to sufficient context, we were unfairly asking him to drive blind.
We can give Heath access to information by augmenting his output with retrieved context. In order to give Heath sufficient context, we pulled information from the Teller documentation and blog and embedded them using the sentence-transformers/all-MiniLM-L6-v2 sentence similarity model. We stored all of these embeddings in a FAISS index using ExFaiss.
One challenge during the embedding process is determining the size of context you want to provide to the generation model. Large language models are easily distracted, so you want to ensure the retrieved context precisely answers the question being asked. If you have time to go through your documentation and precisely partition it into information dense chunks, that’s ideal. Our quick solution to this problem was to chunk documents into 256 tokens each. With this approach, you risk cutting sentences in half; however, we we’re just trying to validate an approach before trying to perfect the process.
Once we had created a sufficient index for Heath to access at inference-time, we moved on to implementing our retrieval and generation servings. Once again, we used Elixir, Nx, and the Bumblebee library. The implementation is relatively simple:
Embed queries using the smaller sentence similarity model
Search the existing ExFaiss index for the document label most similar to the embedded query
Retrieve the top-label and add it to the query as context
Generate an answer for a prompt constructed with the question and context
You can view the full implementation here. You’ll notice it’s only around 100LOC for this entire process.
For this iteration of Heath we used the larger google/flan-t5-xl flan variant with no fine-tuning. The XL model proved to generate more coherent outputs, and was still able to run in a reasonably amount of time on a CPU.
Giving Heath access to context resulted in a big boost in performance. While he would still make up answers from time-to-time, he did significantly better at answering a wide-array of questions about Teller. With what ended up being a few hours of work, we had a decent solution. But, we can do even better still.
Labeling Data With Liveview
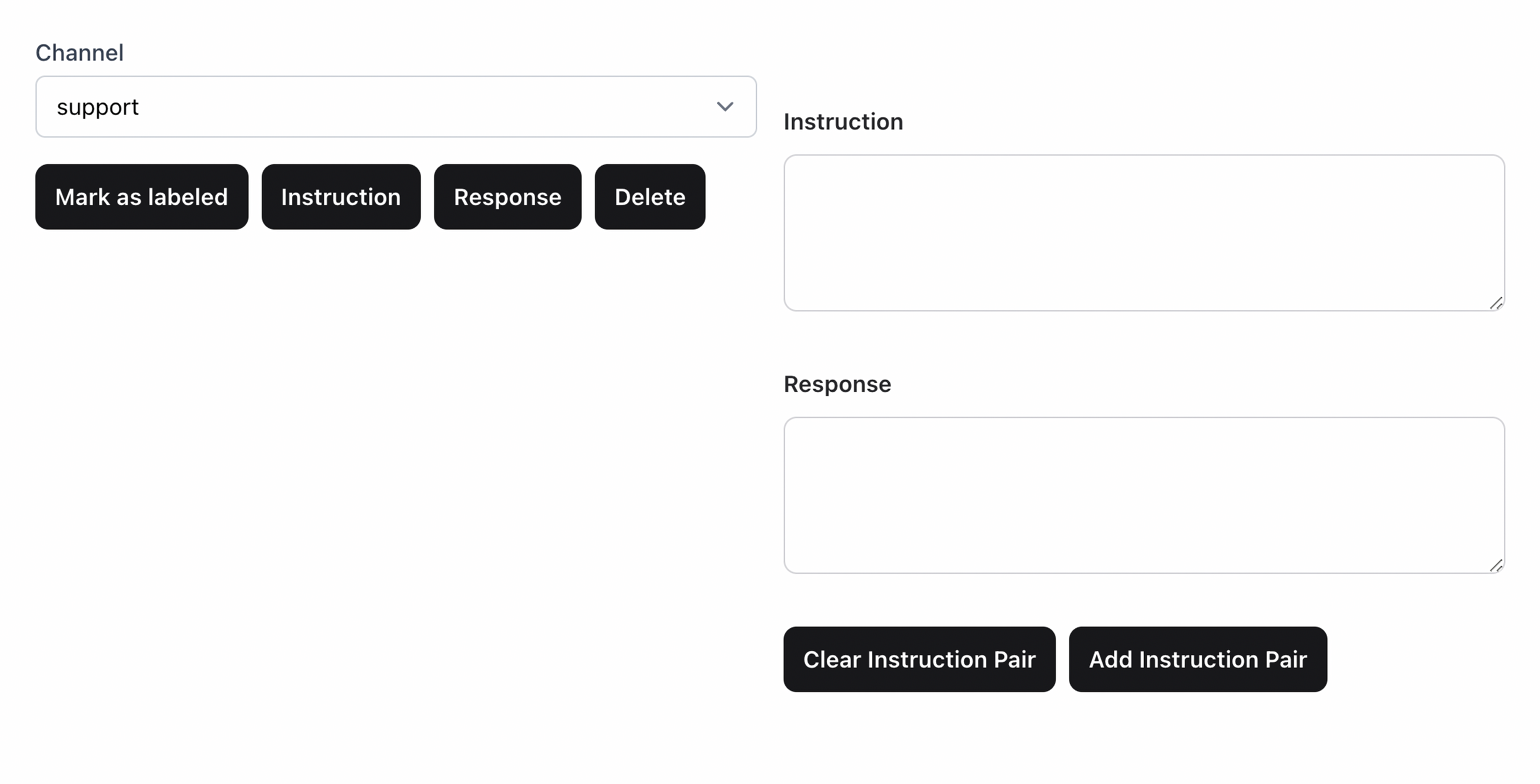
With the idea of Heath validated, it was time to do things properly. We needed to label data. We created a simple LiveView application for labeling instruction-response pairs from Slack data:
A simple labeling LiveView
The idea is that we could pour through information available in Slack to generate a proper dataset for fine-tuning Heath, as well as give him access to more information in his index. The labeling process is tedious and boring, but access to quality data is key to success.
Augmenting Heath’s Training Data
A couple of days after starting the labeling process, we had an idea to artificially increase the size of the dataset we currently had.
A recent trend when working with text is to use large language models like GPT-3 to generate training data. Coming up with support questions and answer pairs from Slack data is relatively easy, but it’s kind of tedious. The first quick augmentation strategy we used was to use the documentation to generate question and answer pairs directly. This strategy is simple: we break the documentation up into small chunks, and then prompt GPT-3 to generate 5 question-answer pairs about the paragraph presented. This results in a quick boost in the amount of available training data. The more documentation you have, the more question-answer pairs you can generate.
For support conversations, another simple augmentation strategy is to use GPT-3 to rephrase support questions. The goal of rephrasal is to generate new copies of the same question without changing the original meaning of the question. In our case, we also asked GPT-3 to rephrase the answer according to the question rephrasal. This was done to stop Heath from learning to be repetitive in his answers.
The final, even simpler augmentation strategy we used is to generate question lists from existing labeled data. One thing we noticed is that in practice a lot of customers come with multiple queries at once, listing out questions like:
What is Teller?
How do I use Teller?
We can generate a fixed number of new instruction-response pairs by randomly selecting multiple existing pairs (say 2-4) and creating a single instruction-response pair comprised of the list of instructions and responses. This strategy actually proved to work pretty well, in practice Heath does a good job of working with question lists.
With these augmentation strategies, we were able to increase the size of our oiginal dataset of about 200 labeled instruction-response pairs to 2000. In practice, you typically don’t want to rely so heavily on augmented data; however, our observations from fine-tuning Heath on the augmented dataset are that he does better than when trained on just our small set of original labels. Our plan is to go back through the augmented set and remove any erroneous entries, and iteratively improve the quality of Heath’s training set.
Bringing Heath to Life
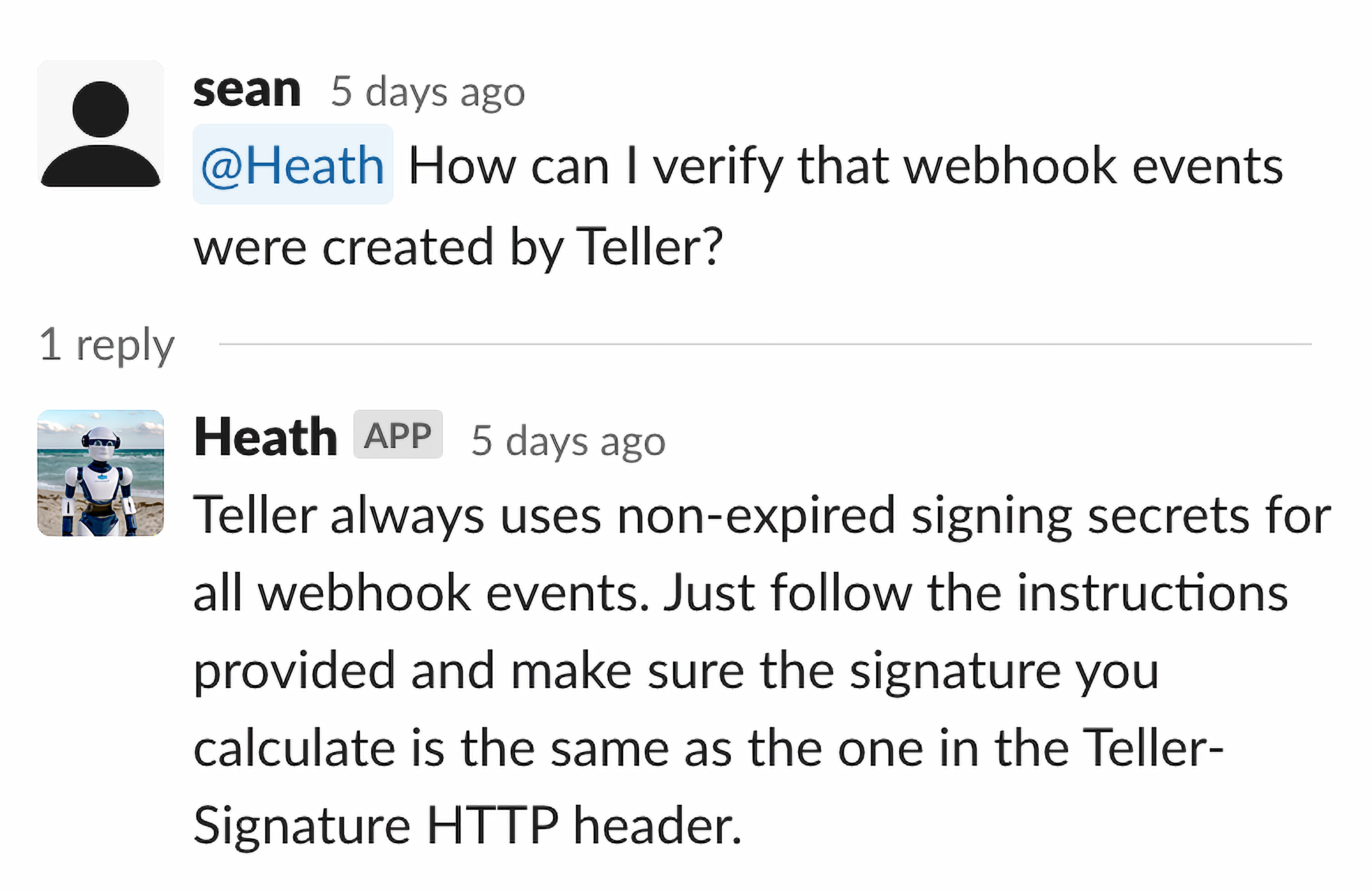
With a validated approach and a trained model, it was time to bring Heath to life. We created a simple slack application which listens for mentions of Heath and replies to the query in a thread:
An example of Heath responding correctly to a question about Teller
An important part of this process is to collect feedback early and often. We also implemented a simple way to give Heath feedback directly from Slack by issuing corrections:
An example correcting Heath on Slack
Right now Heath is in training. In the future, we plan to grow Heath and teach him to use tools, maintain conversations, and more.
We’ve also open-sourced all of the non-Teller specific bits of Heath. This includes Elixir mix tasks for generating datasets from Slack, performing data augmentation, the labeling LiveView, and the actual Phoenix app Heath uses to communicate with Slack. You can find the repository here.
Until now it’s only been possible for third-party financial applications to provide a simple read-only view of a bank account, but we believe in order to provide the most value and utility for end-users, applications must be able to move money too. So that’s why today we’re excited to announce the next step in our journey towards that goal: real-time payment APIs.
These new APIs are built on top of the Zelle network, a real-time P2P network connecting over 1120 banks in the United States, and allow your application to push money directly from a user’s bank account to another US bank account, with the money arriving in the beneficiary’s account in seconds.
Making a payment is one simple API call and the funds arrive in the beneficiary account instantly.
While we expect many new use cases to emerge from the availability of these new APIs, one of the most obvious immediate use cases that we are most excited about is replacing ACH. ACH is commonly used for high-value and recurring payments, and is preferred by many businesses because payment cost is fixed, rather than being a percentage of the payment’s value, as well as being cheaper than plastic card payments. Despite appearing cheaper, ACH has many hidden costs that can quickly add up:
ACH payments take 3-6 business days to clear from the time you submit ACH debit instructions to your bank. So while you can check if the customer has sufficient funds available using our real-time account balance API, there is no guarantee sufficient funds will be available by the time your ACH instructions are processed by the bank. This is a problem if you are shipping goods to users or de facto extending credit to the user before the payment clears, e.g. a brokerage/trading app making funds immediately available to the user.
Individuals have 90 days to dispute the transaction, with some banks allowing up to 120 days. Customers can dispute transactions for reasons such as incorrect or duplicate transaction amounts and fraud. The dispute itself may also be fraudulent, e.g. our brokerage app user crying fraud after losing all of their money during a bad day at the markets. Regardless, if the customer’s bank decides their dispute is legitimate, they will reverse the transfer. This is all the more frustrating for merchants because there is no dispute resolution system in the ACH network. A merchant’s only option is expensive litigation in court.
NACHA rules require account details to be verified by using ACH micro-transactions or Teller’s Verify API before an account can be debited. This adds additional expense and time in the case of micro-transaction based authentication.
Because our payment APIs are real-time you will know instantly whether or not the payment succeeded or not. And because Zelle has no chargeback or reversal mechanisms, payments are one-way and irreversible, eliminating an entire category of fraud and counterparty risk. Finally, no expensive or time-consuming account detail verification is required.
Instead of pulling money from the user’s account by submitting an ACH batch file to your bank, you can directly push it from the user’s account to your by asking the user to connect the account to your application with Teller.
The flow looks like this:
Register your bank account for receiving money from users with Zelle, e.g. payments@your-app.example.com
User connects their account to your app with Teller
Your applications makes an API call to select or add payments@your-app.example.com to the user’s Zelle beneficiaries and send money to that account
You receive money instantly
Our payments APIs are available today and currently supported by our Chase, Bank of America, Citi, and Capital One integrations with support for the rest of our integrations arriving in the coming weeks.
We can’t wait to see what you build.
All product and company names are trademarks™ or registered trademarks® of their respective holders. Their usage does not imply any affiliation with or endorsement by their holders.
At Teller we are building the infrastructure that connects your users’ financial accounts safely and securely to your applications. Because there are few things more sensitive to us all than our financial information, security has been core to everything we do at Teller from before we even wrote the first line of code.
In order for us to successfully deliver on Our Mission we need to earn and maintain customer and end-user trust. We’ve always been committed to adopting and adhering to the highest levels of data security and privacy standards, but providing evidence of our strong security posture and internal controls enables us to prove that we do everything that we say we do. This led us to pursue a SOC 2 audit and certification.
SOC 2 is based on AICPA’sTrust Service Criteria. SOC 2 audit reports focus on an organization’s non-financial reporting controls as they relate to Security, Availability, Confidentiality, Processing Integrity and Privacy of a system. There are two levels of SOC 2 compliance: Type 1 certifies an organizations compliance at a single point in time, and Type 2 that signifies continuous compliance over a minimum period of 6 months.
A SOC 2 Type 2 audit is the gold standard for security compliance and we are pleased to announce that we achieved compliance in December of last year. In achieving SOC 2 Type 2 compliance we maintain our adherence to one of the most stringent, industry-accepted auditing standards for service companies and provide additional assurance to our customers, through an independent auditor, that our business process, information technology and risk management controls are properly designed.
The official audit report provides a thorough review of our internal controls, policies, and processes for our APIs. It also reviews our processes relating to risk management and vendor due diligence, as well as our entire IT infrastructure, software development life cycle, change management, logical security, network security, physical & environmental security, and computer operations.
Teller exists to improve the quality and value of financial services for everyone. Providing developers with tools to connect to existing banking infrastructure is the highest leverage way for us to achieve this.
Before Teller we set out to build a better way to process online payments in the UK by building on something called Faster Payments. By doing so we believed we could reduce the cost of payment acceptance, fraud, and the time it takes for merchants to get their money. Accessing Faster Payments at the time required the sponsorship of a member bank, and as card processing fees generate significant revenue predictably none of them wanted to sponsor us. When we told our friends this they all said “If bank accounts had APIs you could have built this!”, and “I really wish bank accounts had APIs”. So although our original idea wasn’t possible we’d discovered that folks wanted APIs for their bank accounts. But if we couldn’t get one deal done with a payments scheme, doing a deal with every bank we wanted to connect to this hypothetical bank account API platform seemed even more impossible.
The problem was banks didn’t have external APIs… or did they? Sometime later we realized they must exist. It would be the most obvious way to power their own mobile apps. We found that they did but banks had gone to almost absurd lengths to stop 3rd parties using them. Eventually we were making API calls into our own bank accounts and Teller was born.
Today, we don’t partner or have any direct relationships with any bank we provide API access to. Instead we reverse engineer each bank’s mobile app to discover their private APIs and provide access by calling into those directly. We don’t rule out a closer working relationship with banks in the future, but we believe that today our approach results in a better outcome for end-users.
Let me explain why:
1. Banks don’t build great products
Banks are not technology companies, but it’s now more important than ever for every company to be one. Legacy banks fail to deliver the level of product quality we’ve come to expect and the market has not created the incentives for that to change.
Retail banking is dominated by a few large banks. When one innovates, the others react, nobody wins any significant new amount of business, and everyone just compressed their margins for nothing. It’s a zero sum game for them. Smaller banks are unable to innovate lacking the resources to even build their own technology. Reduced to buying core parts of their product like their mobile apps off the shelf from 3rd party vendors.
With this lack of competitive pressure, nobody has the incentive to build great digital products, and it shows. Compare your bank’s app to Instagram, Spotify, Airbnb, or any other top-tier technology company. They’re clunky and slow. Worse they’re usually an absolute mess with dozens of business units competing to have their widget shoe-horned in regardless of whether it serves the user or even makes sense in the context of a banking app.
I'm not interested in staying at the Holiday Inn for 10% off folks. Please just show me my bank account?
A huge opportunity exists for nimble technology startups to build better product experiences and to serve niches big banks will never cater to.
2. Banks don’t provide good value to customers
Banks depend on those with money depositing it in low yield accounts, lending out to those with less at far higher rates, and then charging those with punitive fees for not having any money at all! This is the retail banking business model. Should every customer be charged more or less the same amount to borrow? Is it fair or even necessary to penalize the poorest customers for being poor?
There is massive opportunity to provide better value financial services to customers by using alternative data sources like bank account data to make more accurate and precise credit-risk decisions. New entrants unencumbered by the cost of legacy branch networks, organizational inefficiencies and regulation need to generate less income for the same or better margins, allowing the cost to be passed on to the customer.
3. Direct, first party API integrations are not the solution
The vast majority of use cases for bank account APIs involve providing better value to customers, e.g. by providing a higher earning home for your money or cheaper lending. Most use cases can be distilled down to this. This is directly competitive with the retail banking business model. What makes you think that banks would make great APIs even if they could? Banks don’t want API access to exist, because it opens them up to competition from thousands of more focussed competitors that they will struggle to deal with.
As banks do ship APIs pay careful attention to how much they allow you to effectively compete with them. Do the APIs enable the user to do anything they can do in the bank’s own app? Can you move money? Do the consent flows have great UX or do they look like phishing sites designed to scare users? Are there any troubling terms in your API agreement that gives the bank the ability to dictate what activities you can perform, who you can work with, or to limit or terminate your API access for any reason whatsoever?
I don't know about you but this kinda smells phishy to me.
The biggest problem with first party APIs is that banks will never use them for their own products therefore there is no incentive for them to be reliable, highly available, or able to do everything the bank’s own products can do. Given that the primary use case of a banking API enables competition you might draw your own conclusion that the opposite incentives in fact exist.
Anecdotally, on the day one of our customers switched to Teller, the direct integration API endpoint was down for the biggest bank in the US while Teller was up handling traffic without interruption. They also saw their conversion rates go up significantly after the switch was complete.
Teller gives you the freedom to build whatever you want to build.
4. Regulation is not the answer
Regulators generally make things worse and if they care about good outcomes for customers and competition they should avoid large-scale intervention and broadly leave it to the market to solve.
Regulation creates barriers to entry and compliance requirements that only serve to protect those able to afford it as a cost of excluding competition. Regulators have a tendency to become dominated by the interests they regulate and not the public interest. Every highly regulated industry ends up with the public paying higher prices than less or unregulated industries.
European regulators mandated banks expose APIs and at the same time made more or less everything using bank account data a regulated activity. According to the letter of the law even an app that tracks how much you spend on coffee each week is regulated. Honestly, ask yourselves who does that protect other than incumbent interests? Seeking authorization involves an application fee of thousands of Euros, insurance, own capital requirements, detailed business plans, vendor risk assessments, and disaster recovery plans amongst other things. All this for a coffee spend tracker? Practically speaking this is tens of thousands of Euros to test the viability of an idea before having spent a single cent on developing the idea itself. How many people will discover this and decide it isn’t worth it? When this regulation came into force, we checked how many entities had obtained authorization where we’re from in the UK. It was around 80 for a country of around 65 million people. Regulatory capture unquestionably has a chilling effect on competition.
The regulation in Europe also requires your application to re-obtain consent every 90 days. This means that every 90 days you face churning your customer, made even more likely as they have to go through the bank’s clunky consent process. Banks and fintechs should be competing on an even keel. It’s not fair that fintech startups that have completed a rigorous process and become authorized by a national regulator should have to re-obtain consent every 90 days where the banks themselves don’t have to do this.
Regulation benefits incumbents, not you or end-users.
5. Other providers depend on unreliable technology
Our competition depends on outdated techniques on extracting data from banks known as “screen-scraping”. Essentially this means they go to your bank’s website, log in as you, and scrape the data off the page. Not only is this very slow it can also break in thousands of ways. If you’ve built anything with one of these vendors you will be well aware of the myriad of problems they have and will have earned the gray hairs to prove it. Screen-scraping is so bad these vendors are moving to direct 1st party integrations despite the problems we highlighted above.
Teller uses real APIs, the same APIs that power the bank’s own mobile app. This is a far superior approach resulting in fast, robust, and reliable APIs that don’t break in unexpected ways.
Conclusion
In order to deliver a new wave of innovation and value to the public, fintechs require fast and reliable API access to customer bank accounts. APIs that don’t break in unexpected ways compromising user experience. APIs that let you build what you want, how you want, and for who you want. APIs made for you by us.
As you may or may not know, banks do not generally provide third party developers with API access. This is because providing developers with easy API access to customer accounts means actual competition and ultimately compressed margins. In fairness to banks, building a new API channel costs a lot of money and if all it does is increase competitive pressure why would you spend any time or money on it? It’s a rational response given their incentives.
Despite this people still want to connect their bank accounts to services they trust, and companies still want to build those services.
So, where does this leave us? Thankfully the market has stepped in to provide solutions that enable us all to connect trusted apps with our financial accounts, despite this banks still actively block third party access by blocking their traffic.
All IP Addresses Are Not Created Equal
The way we have solved this is to route our financial institution traffic onto the public internet via mobile phone carrier networks.
The great thing about carrier IP ranges is that carriers have significantly more customers than they have IP addresses, meaning public internet breakout is heavily NAT-ed, i.e. a single address is shared and used by many customers simultaneously. The other great thing is there is good chance you’re on mobile data when you use your bank’s mobile app and your IP address is in the carrier’s IP range.
By sending our traffic onto the internet using the same IP addresses shared by millions of a bank’s own customers using the bank’s mobile app, we both make it significantly more difficult to identify and subsequently block our traffic and we also increase the collateral damage of any hostile action a bank might take against us and our users, i.e. erroneously blocking their own customers using their mobile banking app.
Until recently we used a third party provider for mobile carrier network transit, but suddenly without warning their performance and availabilty degraded to unacceptable levels. Requests occasionally took 20-30 seconds to complete. A single Teller API transaction might actually involve several requests to the financial institution, and even if we can parallelize some of these it’s a disaster for us if any of them take 30 seconds.
Teller provides live access to financial accounts. When you request an account balance, Teller synchronously fetches that data live from the financial institition and returns it to you. Fast and reliable network access is an absolute must in order for us to provide that level of access. Other providers can get away with lesser network performance because they don’t actually ever return live data in an API call. They periodically poll the institution a couple of times a day, and give you the most recent data they have when you make your API call.
We immediately began to design and build an in house solution to solve this problem once and for all.
Introducing Telnet
Telnet is our propietary mobile carrier proxy network. The name is a portmanteau of Teller Network, but if we’re honest it began as an internal joke as it’s built on top of SSH, the remote access protocol that obsoleted the original Telnet.
Telnet is composed of a large number of edge nodes, which are single board Linux computers with LTE modems attached running our own software written using Nerves. When nodes boot they reverse SSH into our network and register themselves as available to route API traffic. Our infrastructure then routes our financial institution traffic via our Telnet edge nodes, egressing onto the internet on carrier IP ranges.
It works amazingly well. We have not only cut the latency overhead to the bone, according to our logs requests failing due to proxy errors have become a thing of the past too.
Credit goes to the team for shipping this so quickly. They went from bare git repo to production deployment of a fleet of embedded devices with OTA software updates in weeks. I’m very proud of them.
Follow @teller for a future blog post on how we built Telnet.
Today we are excited to share with you an easy, low risk way to migrate your app away from relying on unreliable legacy screenscraping providers to enjoy the increased reliability and higher performance of Teller’s next generation bank API integrations.
From the earliest conversations we had with users we learned many of you are unhappy with your current provider, want an alternative solution, but feel trapped because your provider locks you in by requiring you to use their user onboarding flow.
Providing a Path to Move Forward
We’ve added the ability for your app to skip the initial Teller branded consent and institution picker screens, meaning that the first screen presented to the user is the initial institution screen.
The implementation is very simple. Simply declare skipPicker: true in the Teller Connect setup function and later specify the institution when calling TellerConnect.open().
Many of you reading this will be Plaid customers. By combining this simple concept with Plaid’s event callbacks for example, your app now has access to live real-time data, and reliable connections by using Teller for the majority of your users, while still providing the base level of legacy experience for your long tail customers.
Demo
Let’s take a look at this video demo to understand how this works in practise. Notice how the user journey begins in Plaid and seamlessly switches to Teller as soon as the user picks a bank Teller supports.
This migration strategy is a great starting point to test the Teller waters. First, why not try us for an institution that simply doesn’t work on Plaid, e.g. Capital One. As you experience first hand the difference in quality Teller provides you can move over more and more of your users to Teller. Of course while this is happening we will continue to aggressively work on expanding our coverage so falling back to Plaid or another provider becomes less and less relevant.